In this tutorial lets get started to learn some basics about PIG. If you recall from previous tutorial PIG is a script based utility to write transformations e.g Agg , Join etc
similar to SQL it is for people who are more comfortable in SQL then
Java. But you can also make UDF for complex transformation which are
written in Java and called directly in PIG.
If you are new to Hadoop please go through http://tahir-aziz.blogspot.com/2013/07/introduction-to-big-data-and-hadoop.html
Our current case study which we want to implement is a very simple example we want to compuet the average Stock Volume for IBM company .From last tutrial we loaded the Stock exchange data and we would use the same to complete this.
Refer to the blog to http://tahir-aziz.blogspot.com/2013/08/getting-started-with-hadooploading-data.html
To write our first PIG script follow below steps.
Thanks
Tahir Aziz
If you are new to Hadoop please go through http://tahir-aziz.blogspot.com/2013/07/introduction-to-big-data-and-hadoop.html
Our current case study which we want to implement is a very simple example we want to compuet the average Stock Volume for IBM company .From last tutrial we loaded the Stock exchange data and we would use the same to complete this.
Refer to the blog to http://tahir-aziz.blogspot.com/2013/08/getting-started-with-hadooploading-data.html
To write our first PIG script follow below steps.
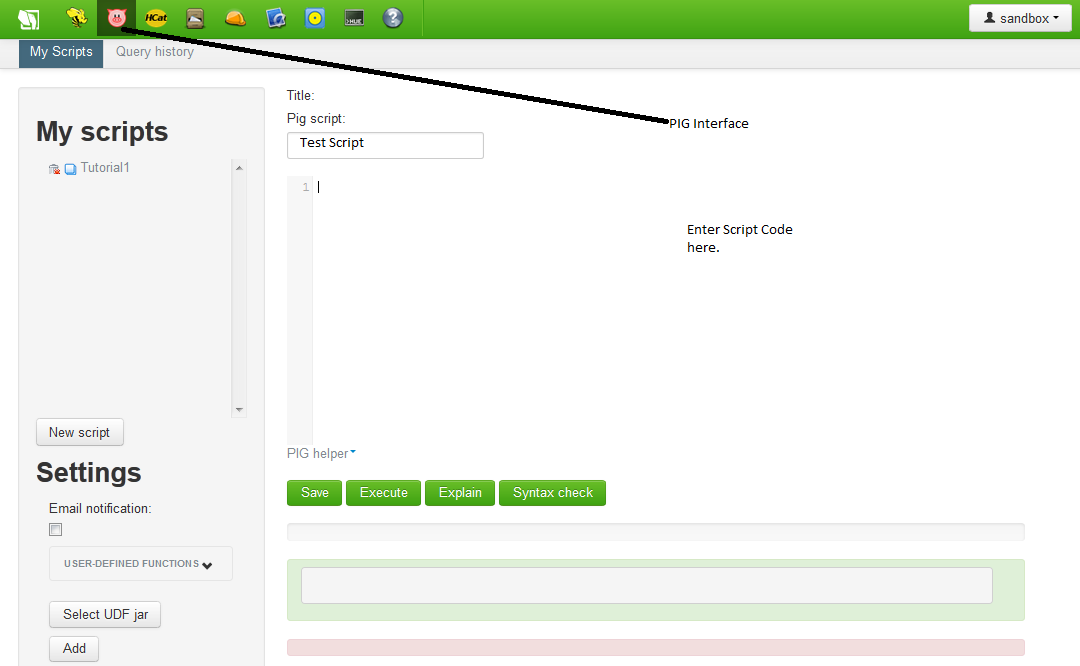
- Login to your Horton Sandbox and on Main screen Click on "Pig" icon. Refer to diagram below

- You can create your first script by entering the Script Name and in the middle of the screen you can see Editor where you should actually code the logic.
- Enter below script into Editing Area
- A = LOAD 'nyse_stocks_t' USING org.apache.hcatalog.pig.HCatLoader(); // Load the file into a variable A but make a note that the file should be first loaded using File Uploader at /User/SandBox.
B = FILTER A BY stock_symbol == 'IBM'; // Filter data for IBM only
C = GROUP B all; // Simple Group by function on ALL columns
D = FOREACH C GENERATE AVG(B.stock_volume); // Iterate records to calculate Average using AVG function.
dump D; - Click on "Save" to save this script to sandbox.
- Later you can Open the script and "Execute" to make sure it works fine. The expected result is
(7915934.0)
Thanks
Tahir Aziz
No comments:
Post a Comment